The Challenge of Identifiers
In software engineering, choosing a Primary Key type seems simple, but it profoundly affects both security and system performance as you scale. We typically start with two familiar choices: Auto-increment Integers or UUIDv4.
1. Limitations of Traditional Methods
Option 1: Auto-increment Integer
-- Example: Sequential IDs over time
1, 2, 3, 4, 5...
- Pros: Extremely fast and memory-efficient.
- Cons: Lack of security. If your URL is
https://api.myapp.com/v1/invoice/1001, a competitor can easily guess that the next invoice is1002, or even count your total customer base just by incrementing these numbers.
Option 2: UUIDv4 (Random String)
-- Example: No discernible order
f47ac10b-58cc-4372-a567-0e02b2c3d479
0e58c3d4-a567-4372-58cc-f47ac10b0e02
- Pros: Maximum security; impossible to predict.
- Cons: Database Fragmentation. Because it is entirely random, the Database must work hard to sort these into memory, slowing down the system as your data grows.
2. UUIDv7: The Best of Both Worlds
UUIDv7 solves these problems by combining: [Current Timestamp] + [Random Bits].
-- UUIDv7 Example: Always increasing over time
018f3a5b-7a12-7b3e-8a5c-1234567890ab -- Created at 10:00:00
018f3a5b-7a13-7b3e-8a5c-fedcba987654 -- Created at 10:00:01
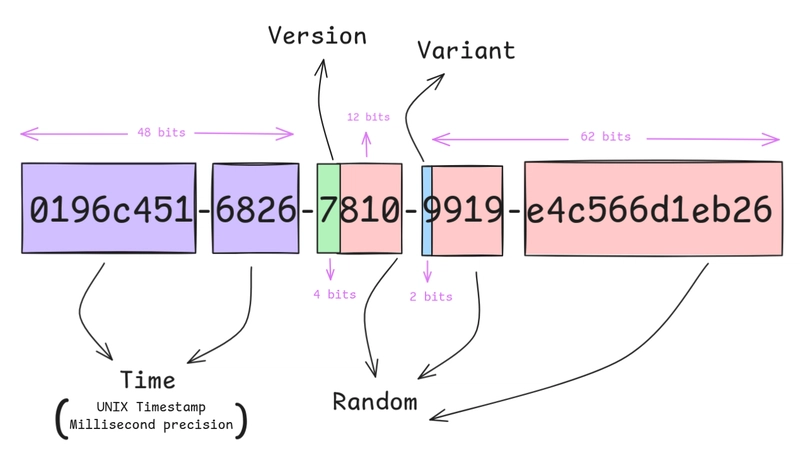
 Figure 1: The detailed structure of UUIDv7 enables efficient data sorting.
Figure 1: The detailed structure of UUIDv7 enables efficient data sorting.
- Why is it fast? Because the prefix is a timestamp, IDs created later are always “larger” than those created earlier.
- Why is it secure? The random suffix is large enough to prevent guessing the next ID.
3. Database Performance and B-Tree Indexing
To understand why UUIDv7 is fast, we need to understand B-Trees.
What is a B-Tree?
Imagine the Database is a massive library. To find books quickly, the librarian sorts them on shelves in order (e.g., A to Z). When you bring a new book, the librarian must find the exact spot to insert it.
- With UUIDv4 (Random): It’s like bringing 100 books with random starting letters. The librarian has to run back and forth between shelves, shifting old books aside to squeeze new ones in the middle. This is called Fragmentation.
- With UUIDv7 (Time-ordered): It’s like new books always starting with the next letter in the alphabet. The librarian simply stacks them at the end of the last shelf. It’s incredibly fast and tidy.
=> Result: UUIDv7 helps the Database write data faster and significantly reduces Disk I/O load.
4. Standardization and the Future
UUIDv7 officially became a standard in RFC 9562 (May 2024).
- PostgreSQL 18 now supports the
uuidv7()function natively. - Libraries for Java, Go, Python, and Rust are production-ready.
- Distributed Systems are prioritizing UUIDv7 for decentralized data identification.
Conclusion
UUIDv7 is the perfect “sweet spot” between the security of UUIDv4 and the performance of Integers. If you are starting a new project, consider using UUIDv7 from the beginning to ensure your system is ready for future scale.
Are you planning to switch to UUIDv7? Share your thoughts below!